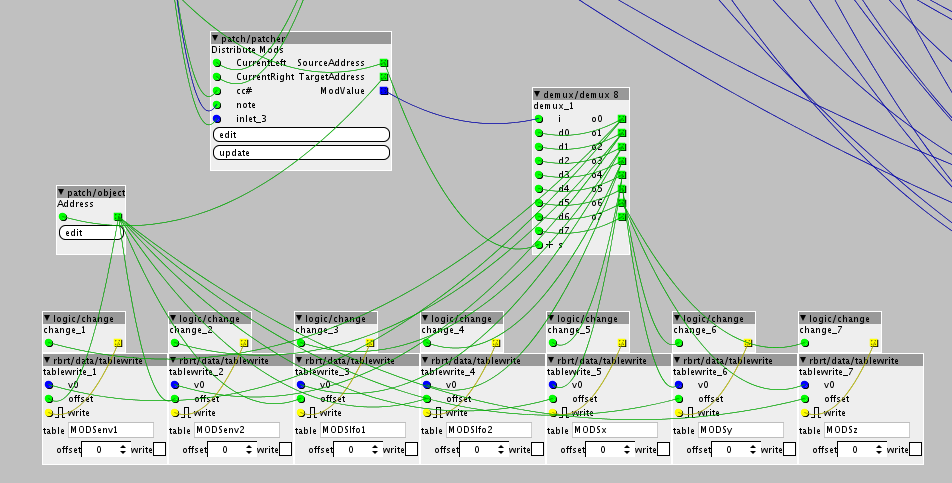
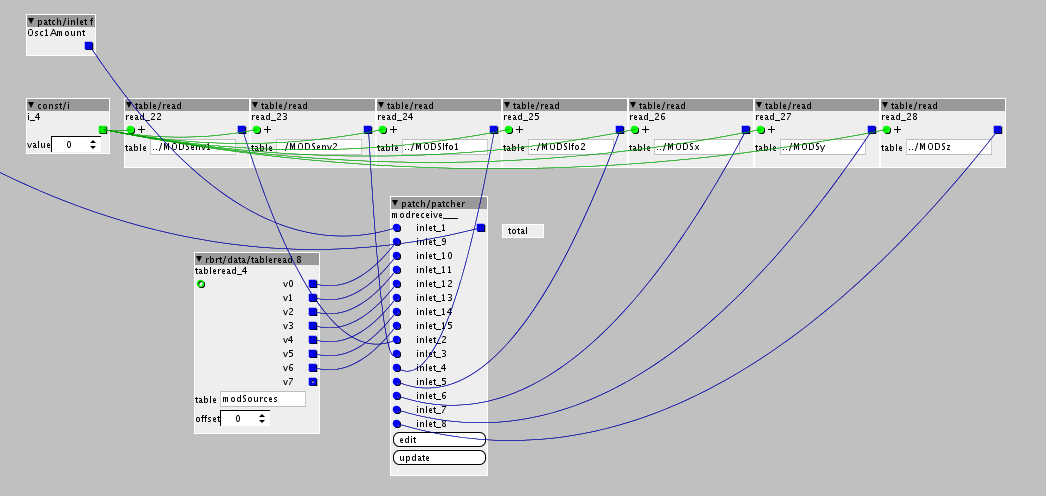
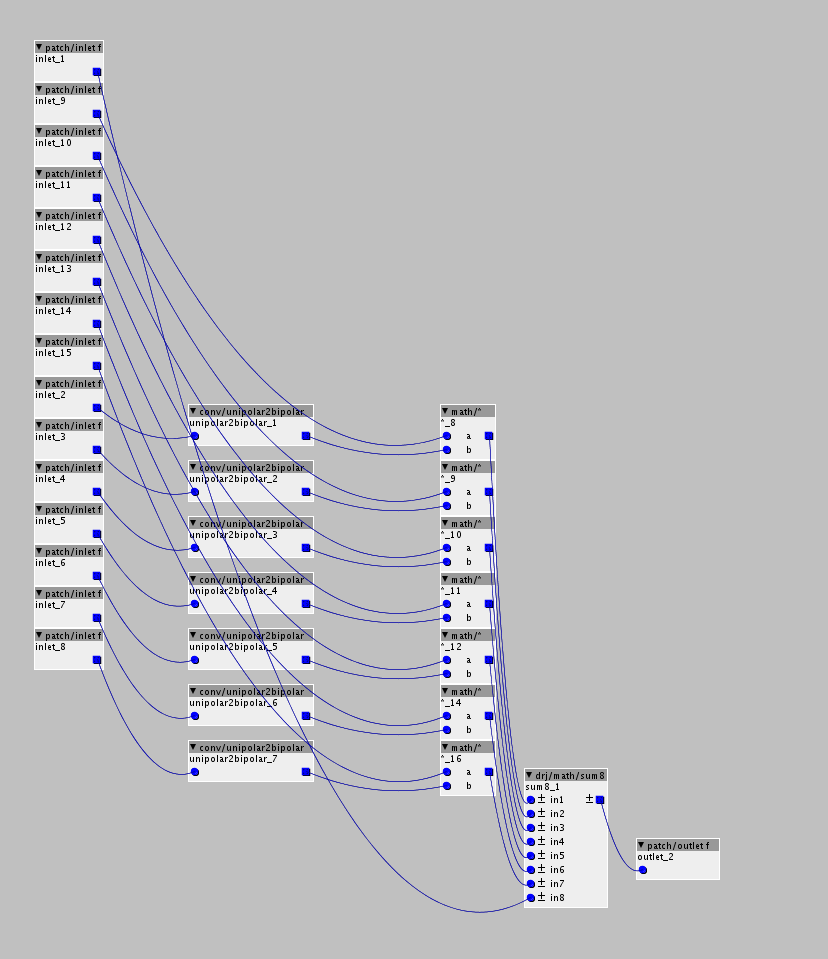
Hello wonderful Axo community.
I'm new to coding. I've made a couple of variants of an object meant to encapsulate the functionality of a subpatch I was using that was too sram expensive.
The first version I made declared several variables and was not very efficient memory wise.
So I tried to put the whole thing into one equation, without declaring any variables and this saves a lot of memory (only using about half), but uses too much DSP resources and I end up overloading.
would like to know what would be the best way of approaching this.
Here is the original code with a bunch of variables, hungry for memory:
int te1 = attr_t1.array[_USAT((attrtarget),attr_t1.LENGTHPOW)]<<attr_t1.GAIN;
int te2 = attr_t2.array[_USAT((attrtarget),attr_t2.LENGTHPOW)]<<attr_t2.GAIN;
int tl1 = attr_t3.array[_USAT((attrtarget),attr_t3.LENGTHPOW)]<<attr_t3.GAIN;
int tl2 = attr_t4.array[_USAT((attrtarget),attr_t4.LENGTHPOW)]<<attr_t4.GAIN;
int tx = attr_t5.array[_USAT((attrtarget),attr_t5.LENGTHPOW)]<<attr_t5.GAIN;
int ty = attr_t6.array[_USAT((attrtarget),attr_t6.LENGTHPOW)]<<attr_t6.GAIN;
int tz = attr_t7.array[_USAT((attrtarget),attr_t7.LENGTHPOW)]<<attr_t7.GAIN;
int bpe1 = (te1-(1<<26))<<1;
int bpe2 = (te2-(1<<26))<<1;
int bpl1 = (tl1-(1<<26))<<1;
int bpl2 = (tl2-(1<<26))<<1;
int bpx = (tx-(1<<26))<<1;
int bpy = (ty-(1<<26))<<1;
int bpz = (tz-(1<<26))<<1;
int se1 = attr_ms.array[_USAT((0),attrms.LENGTHPOW)]<<attr_ms.GAIN;
int se2 = attr_ms.array[_USAT((1),attrms.LENGTHPOW)]<<attr_ms.GAIN;
int sl1 = attr_ms.array[_USAT((2),attrms.LENGTHPOW)]<<attr_ms.GAIN;
int sl2 = attr_ms.array[_USAT((3),attrms.LENGTHPOW)]<<attr_ms.GAIN;
int sx = attr_ms.array[_USAT((4),attrms.LENGTHPOW)]<<attr_ms.GAIN;
int sy = attr_ms.array[_USAT((5),attrms.LENGTHPOW)]<<attr_ms.GAIN;
int sz = attr_ms.array[_USAT((6),attrms.LENGTHPOW)]<<attr_ms.GAIN;
int e1 = ___SMMUL(bpe1<<3,se1<<2);
int e2 = ___SMMUL(bpe2<<3,se2<<2);
int l1 = ___SMMUL(bpl1<<3,sl1<<2);
int l2 = ___SMMUL(bpl2<<3,sl2<<2);
int xt = ___SMMUL(bpx<<3,sx<<2);
int yt = ___SMMUL(bpy<<3,sy<<2);
int zt = ___SMMUL(bpz<<3,sz<<2);
outlet_total = e1 + e2 + l1 + l2 + xt + yt + zt + inlet_initial;
Here is the second one that is one equation, more memory efficient, but dsp hungry.
outlet_total =
(__SMMUL((((attrt1.array[USAT((attr_target),attr_t1.LENGTHPOW)]<<attr_t1.GAIN)-(1<<26))<<1)<<3,(attr_ms.array[USAT((+ 0),attr_ms.LENGTHPOW)]<<attr_ms.GAIN)<<2))+
(__SMMUL((((attrt2.array[USAT((attr_target),attr_t2.LENGTHPOW)]<<attr_t2.GAIN)-(1<<26))<<1)<<3,(attr_ms.array[USAT((+ 1),attr_ms.LENGTHPOW)]<<attr_ms.GAIN)<<2))+
(__SMMUL((((attrt3.array[USAT((attr_target),attr_t3.LENGTHPOW)]<<attr_t3.GAIN)-(1<<26))<<1)<<3,(attr_ms.array[USAT((+ 2),attr_ms.LENGTHPOW)]<<attr_ms.GAIN)<<2))+
(__SMMUL((((attrt4.array[USAT((attr_target),attr_t4.LENGTHPOW)]<<attr_t4.GAIN)-(1<<26))<<1)<<3,(attr_ms.array[USAT((+ 3),attr_ms.LENGTHPOW)]<<attr_ms.GAIN)<<2))+
(__SMMUL((((attrt5.array[USAT((attr_target),attr_t5.LENGTHPOW)]<<attr_t5.GAIN)-(1<<26))<<1)<<3,(attr_ms.array[USAT((+ 4),attr_ms.LENGTHPOW)]<<attr_ms.GAIN)<<2))+
(__SMMUL((((attrt6.array[USAT((attr_target),attr_t6.LENGTHPOW)]<<attr_t6.GAIN)-(1<<26))<<1)<<3,(attr_ms.array[USAT((+ 5),attr_ms.LENGTHPOW)]<<attr_ms.GAIN)<<2))+
(__SMMUL((((attrt7.array[USAT((attr_target),attr_t7.LENGTHPOW)]<<attr_t7.GAIN)-(1<<26))<<1)<<3,(attr_ms.array[USAT((+ 6),attr_ms.LENGTHPOW)]<<attr_ms.GAIN)<<2))+
inlet_initial;
How should I approach making this more efficient. They both work. But I need 192 of them in my patch, so they need to be as efficient as possible.
I still lack a lot of the coding concepts. Perhaps there is another assembler instruction I can use?
Any help welcome!