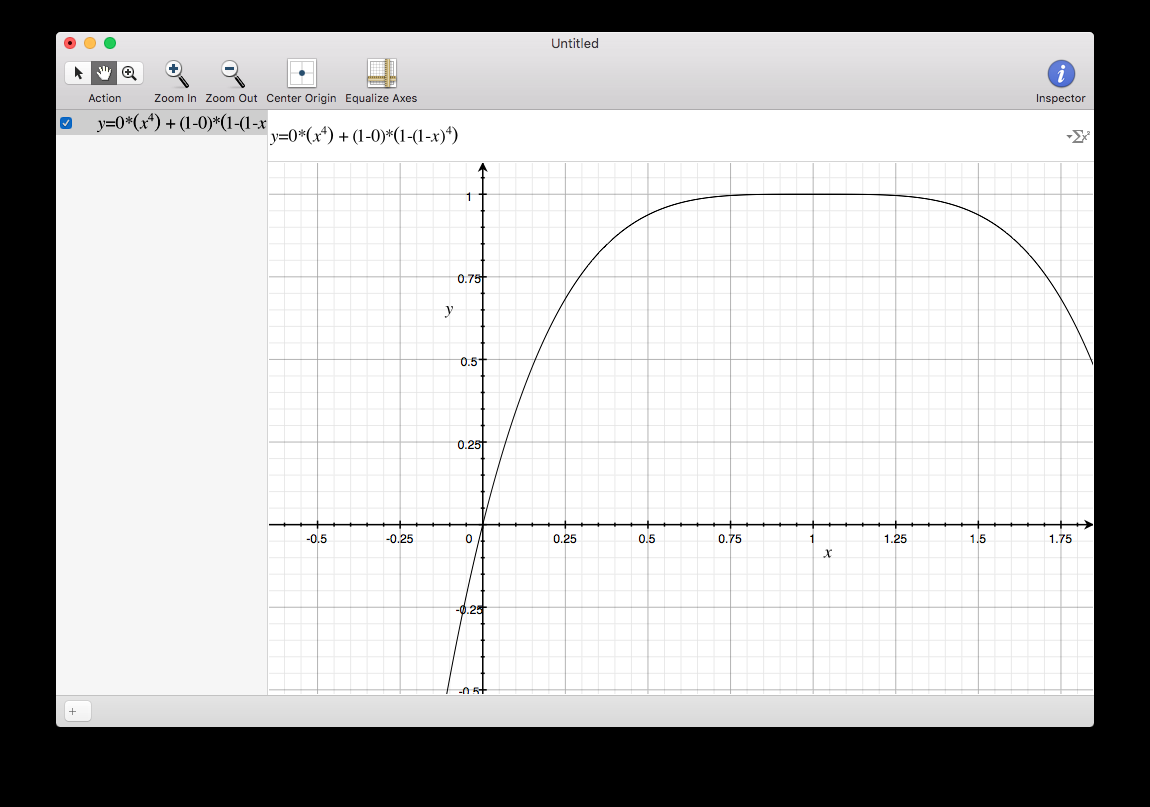
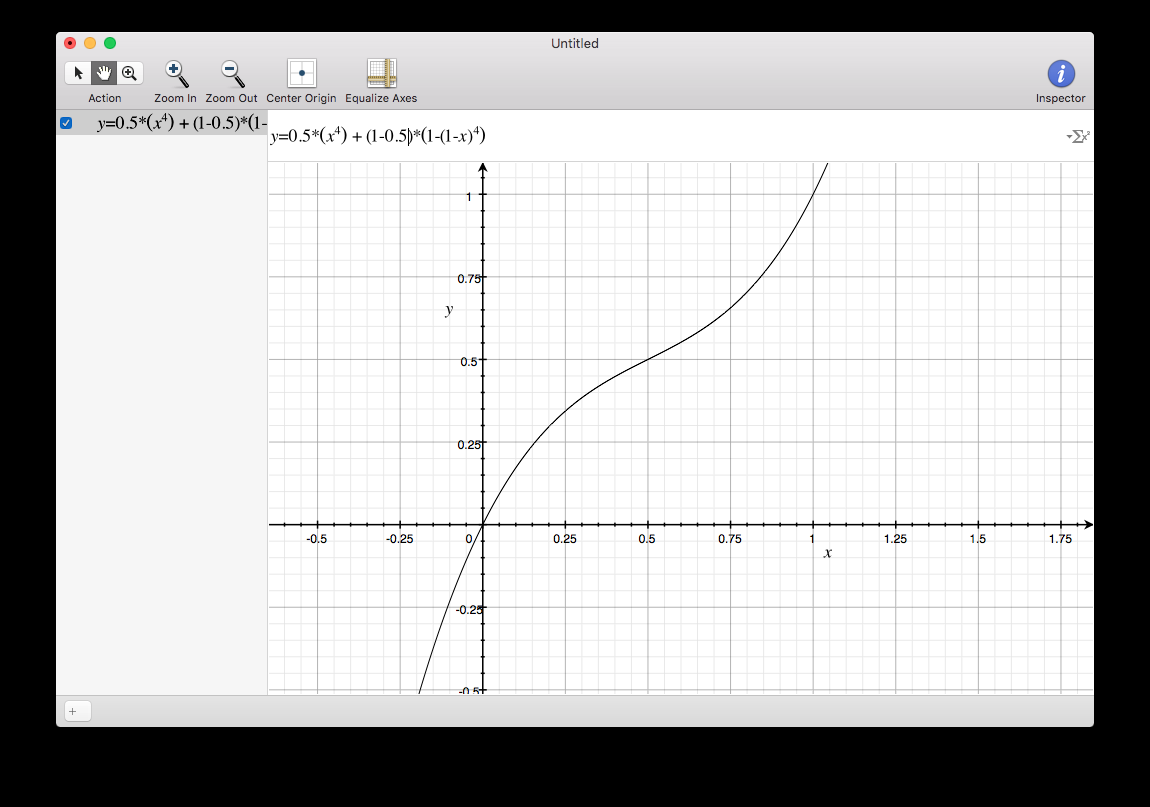
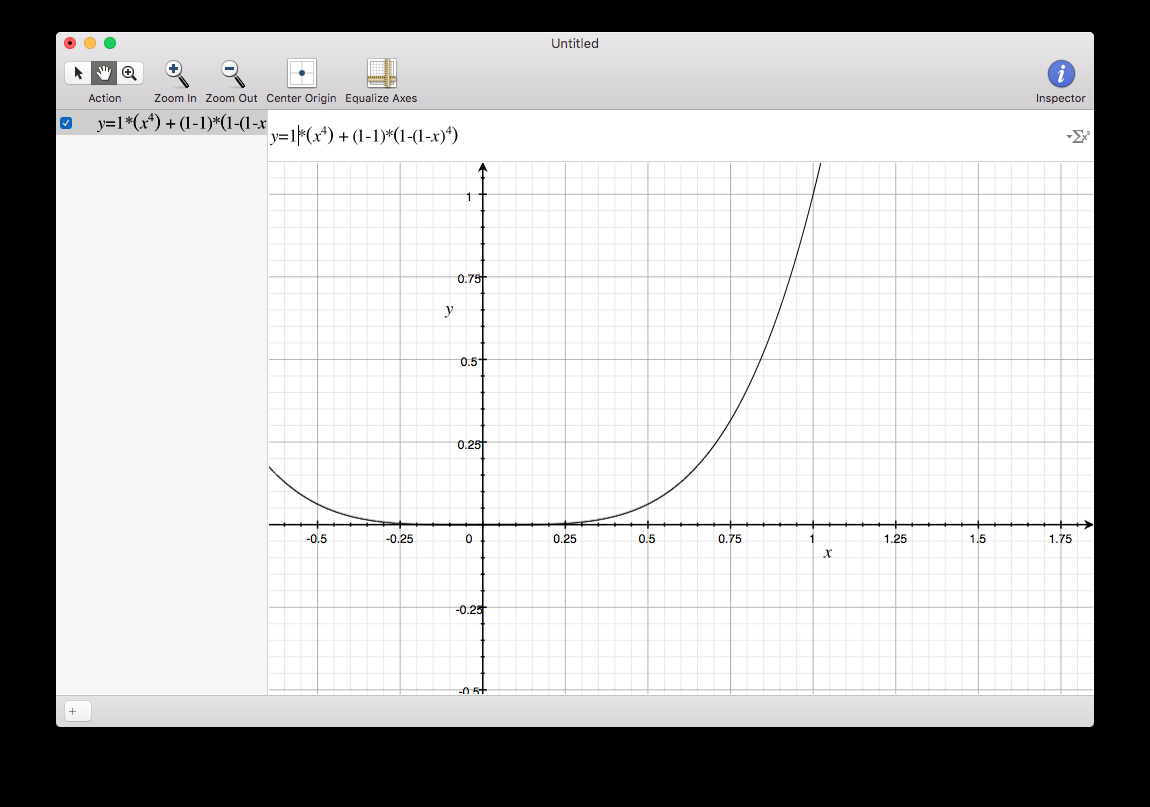
This one is more extreme. Think I prefer the previous equation.
a|x

yeah, I noticed the S at 0.5 too... think id prefer less extreme curves, but with a proper linear behaviour.
... I guess, I can just throw one of them in for now, always can be altered/fine tuned later.
I guess the 'efficiency' side, will also depend how you use it... if you only have a few as a function generator (which was the use-case i had in mind originally) its not too critical, but if you want to use if for envelopes with polyphonic voices then its going to have to be efficient, as there are many more in use.
Don't expect any issues with adding that, pull request welcome!
I don't think the s-shape would be noticeable, I think the most important properties are the derivative continuities at x=0 and x=1.
Maybe two parameters would be nice, one for the derivative at x=0 and one for the derivative at x=1?
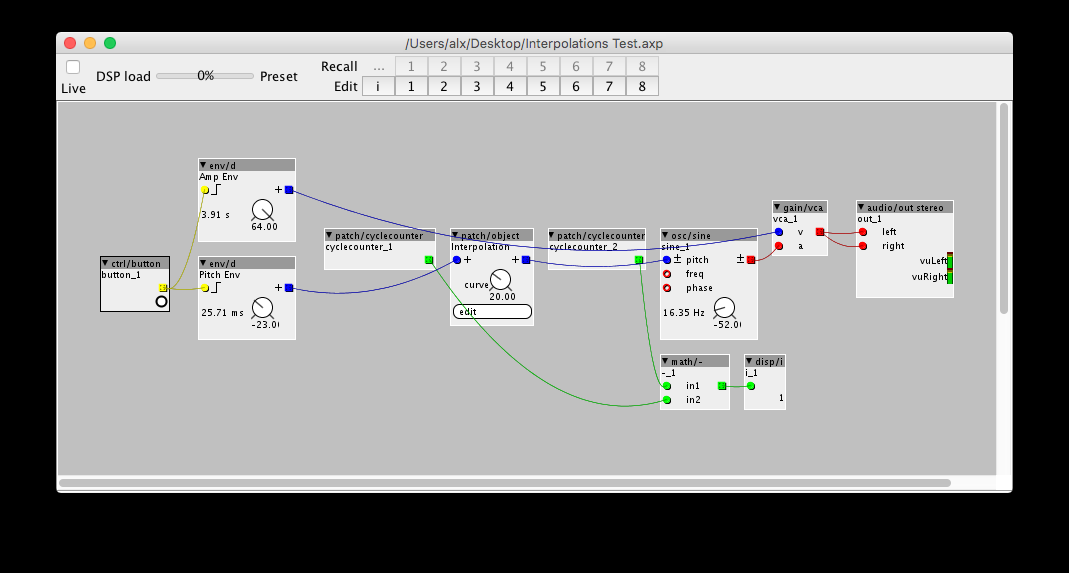
I made a little test with the basic square/square-root approximation.
Interpolations Test.axp (4.5 KB)
Not sure I have the cycle counter objects setup right, but it seems to be reporting 1 cycle, which seems unlikely.
a|x
How about a Cubic Bezier? You'd need 4 parameters, for the X and Y values of the 'handle' for the two points.
You'd probably want to constrain the handles so the curve stayed within the 0 > 1 range.
a|x
I have some home grown intrinsics that may help with the conversion. I meant to post it earlier today, but got distracted. This ARM generation is much newer than the ones I used to work with back in the days, so someone please look over it. Seems to do the right thing though, taking two cycles.
<code.declaration><![CDATA[
__attribute__( ( always_inline ) ) __STATIC_INLINE float ___VCVT_F32_S32 ( int32_t op1, int32_t op2 )
{
float result;
__ASM volatile ( "vmov %0,%1\n"
"vcvt.F32.S32 %0, %0, %2\n"
: "=w" (result)
: "r" (op1), "i" (op2)
);
return(result);
};
__attribute__( ( always_inline ) ) __STATIC_INLINE int32_t ___VCVT_S32_F32 ( float op1, int32_t op2 )
{
int32_t result;
__ASM volatile ( "vcvt.S32.F32 %1, %1, %2\n"
"vmov %0,%1\n"
: "=r" (result)
: "w" (op1), "i" (op2)
);
return(result);
};
]]></code.declaration>Is super-expensive, using pow()
float outf = pos * (pow(inf, 4)) + (1 - pos) * (1 - pow(1 - inf, 4));
Peaks at 40% CPU with my basic test patch.
Interpolations Test 2.axp (4.5 KB)
a|x
hmm, the compiler is probably moving the operations to somewhere else...
A quick workaround to prevent this is addingasm volatile("mov r0, r0");
before and after your code. The optimizer can't move code across this barrier. I think I should include it in the cyclecounter object. reference: http://www.ethernut.de/en/documents/arm-inline-asm.html
Beziers do not express nicely as an y=f(x) function, they're not strictly single valued.
do you think it might be worth linking the CMSIS power methods into the firmware, and comparing...
arm_power_q15 , could be interesting to compare.
whats your general thoughts on including more of the CMSIS library? seems it might be handy and easy to use for many... Im not sure how it efficient it is, but perhaps useful for where performance is not critical, and for 'simpler' uses?
No pow(), expand x^4 to x*x*x*x, hopefully the compiler recognizes this as (x*x)*(x*x) and then it's only two multiplies away.
Replaced with
float outf = pos*(inf*inf*inf*inf)+(1-pos)*(1-(1-inf)*(1-inf)*(1-inf)*(1-inf));
Much better!
a|x
Interpolations Test 3.axp (4.5 KB)
Do you mean void arm_power_q15()?
/**
* @brief Sum of the squares of the elements of a Q15 vector.
* @param[in] *pSrc points to the input vector
* @param[in] blockSize length of the input vector
* @param[out] *pResult sum of the squares value returned here
* @return none.
*/It's unrelated to the pow(x,y) math function...
This is my variant (in axoloti-contrib/patches/jt/devel/float_workbench.axp):
__attribute__ ( ( always_inline ) ) __STATIC_INLINE float Q27ToF(int32_t op1) {
float fop1 = *(float*)(&op1);
__ASM volatile ("VCVT.F32.S32 %0, %0, 27" : "+w" (fop1) );
return(fop1);
}
__attribute__ ( ( always_inline ) ) __STATIC_INLINE int32_t FToQ27(float fop1) {
__ASM volatile ("VCVT.S32.F32 %0, %0, 27" : "+w" (fop1) );
int32_t r = *(int32_t*)(&fop1);
return(r);
}This includes the Q27 scaling for free.
I left the data move to the freedom of the compiler, the M4 can also move two core registers to two fpu registers in one instruction.
There may be fixed-point/integer implementations though, and you can set the Y coordinate of your end point to an arbitrary number, so you don't need to scale afterwards.
a|x
The Bezier function:
x(t) = (1 - t)^3*x1 + 3*(1 - t)^2*t*x2 + 3*(1 - t)*t^2*x3 + t^3*x4
y(t) = (1 - t)^3*y1 + 3*(1 - t)^2*t*y2 + 3*(1 - t)*t^2*y3 + t^3*y4can you convert that to
y=f(x) ?
I believe a solution to
"two parameters one for the derivative at x=0 and one for the derivative at x=1?"
should exist that is way less complex than bezier.
I'm waaaay out of my depth here, but isn't 't' (time/curve-completion) the value that would be your input, rather than x?
You should be able to simplify the function down to 1D, in which case, you'd only need two parameters for the handles, since start/end points are fixed at 0/[maxvalue].
a|x
I agree that it's better to let the compiler do the data move. It's still useful be able to pass in the scaling since one does not always want Q27 - the passing of the scaling as an immediate operand is also free in the sense of needing no extra cycles.
Perhaps it would be good to make both Q27ToF(int32_t op1) and FixToFloat ( int32_t op1, int32_t scale ) variants available in firmware/axoloti_math.h?
Ah I missed op2 in your code, I'm surprised it is possible to export that opcode field to a generic C function!
Certainly considering inclusion in axoloti_math.h, still I feel it needs a bit more testing to be confident...